Cai, Zixian, et al. "Synthesizing optimal collective algorithms." Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. 2021.
どんなもの?
- トポロジが与えられたときに、そのトポロジに適した集団通信アルゴリズムをSMT(Satisfiability modulo theories)の形式で定式化して求めた
- 求めたアルゴリズムを元にコード生成
- DGX-1(NVIDIA)、Gigabyte Z52(AMD)で実験、手動でチューニングされたアルゴリズムと同等以の性能を実現
詳細
論文メタ情報
- [github], [site]
- MSCCL is the product of many great researchers and interns at Microsoft Research. Below is a list of our publications:
- GC3: An Optimizing Compiler for GPU Collective Communication -- ASPLOS'23
- Synthesizing optimal collective algorithms -- PPoPP'21 (Best Paper Award)
- Breaking the Computation and Communication Abstraction Barrier in Distributed Machine Learning Workloads -- ASPLOS'22
- TACCL: Guiding Collective Algorithm Synthesis using Communication Sketches -- NSDI'23
- SMTソルバはMicrosoft内製Z3を使用
AI向けハードウェア
DGX-1
深層モデル学習用に専用のハードウェアが開発されています。 例えばNVIDIA DGX-1*1では8つのGPUをNVLINKで結合させている。 ちなみに下記の構造では6つの片方向Ringに分解可能であり、Ringベースのアルゴリズムもbroadcastベースのアルゴリズムのどちらにも強そうな見た目をしていますね。

Gigabyte Z52

背景
トポロジに適した集団通信アルゴズムを追及するのは重要
- AI学習用に新しくAccelarator(GPU)間の高速インターコネクトが開発
- 分散深層学習ワークロードにおいて集団通信が多くの時間を占める
- 例えば、Megatron言語モデルを訓練するのに30%の時間がAllReduce集団通信に費やされていた
- しかし、インターコネクトによって効率的な通信アルゴリズムも異なり、現状、ハードウェアごとに手作業で集団通信アルゴリズムがチューニングされている
そのためインターコネクトのトポロジに応じて集団通信アルゴリズムを自動にチューニングできないか?というのがこの論文のモチベーション
手法
集団通信のタイプ分け
| type | collectives |
|---|---|
| non-combining | gather, scatter, all-to-all, all-gather |
| combining | reduce, all-reduce, reduce-scatter |
- non-combining: データをそのまま転送する
- combining: (結果的に)簡約されたデータを保持する、データを簡約した状態で送信することが転送量を節約することができる
提案手法の流れとしては下記。
- non-combining集団通信のアルゴリズムをSMTで求める
- combining集団通信はnon-combiningの結果を逆転(inverse)させて求める
用語
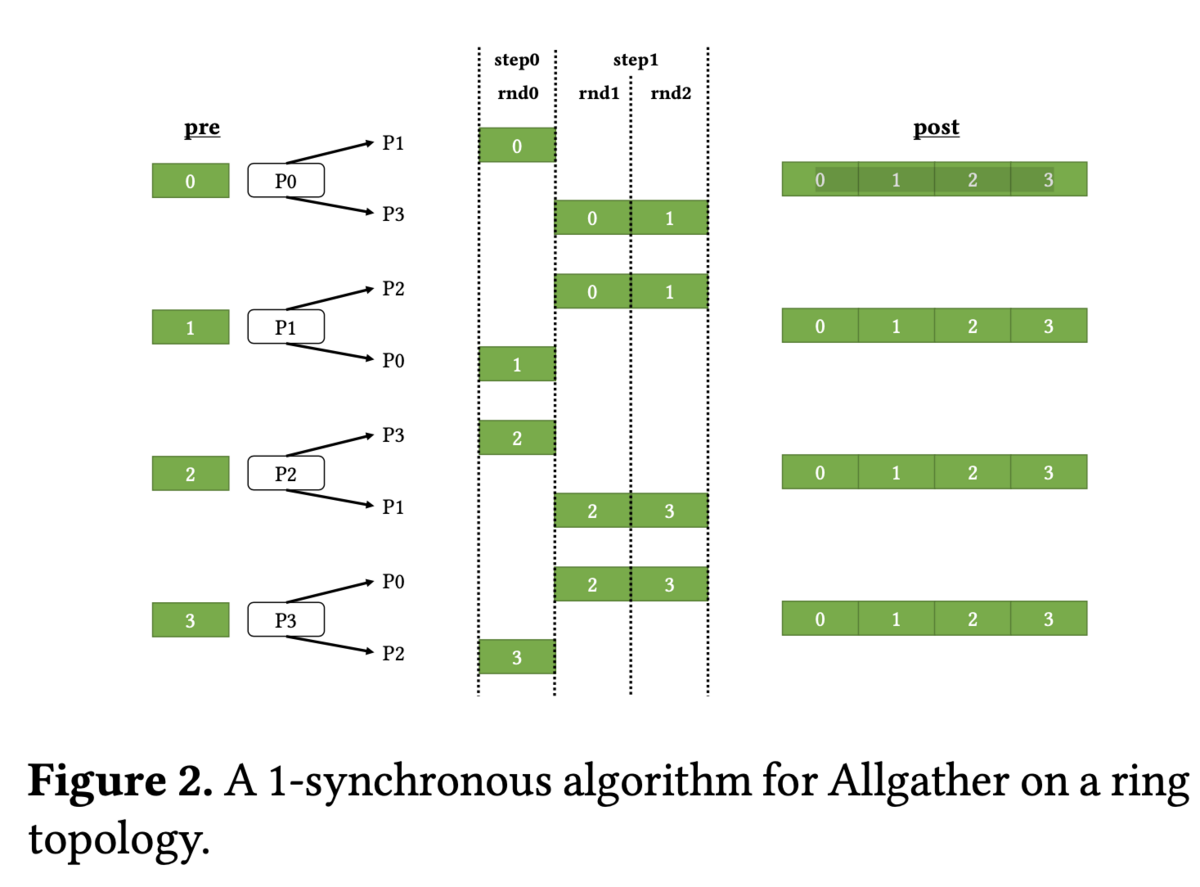
図は双方向リングにおけるall-gatherの実行図
- chunk: データの分割数 -- 図では4
- step: 同期単位
- round: 1chunkデータの送信単位
- stepごとに異なっても良い
- 図ではstep 0では1 round, step 1では2 roundが実行されている
最適化
変数
- S: step数, R: round数, C: chunk数は固定(ハイパーパラメータ)
- (1) どのchunkデータを (2) どのタイミングで (3) どのノードからどのノードに送るか、が最適化対象
- 変数
- time$_{c, n} \in {0, \ldots, S}$: ノードnがどのstepでchunkデータcを受け取るか
- snd$_{n, c, n'} \in {0, 1}$: ノードnがchunkデータcをノードn'に送るか否か
*2 = Trueならば、ノードnがchunkデータcをノードn'にstep sで受け取る
目的関数
2種類の目的関数のパレート解を求める
- Latency cost = $S \alpha$
- α: 転送の初期化コスト, 式は総初期化コスト(同期数 = step数)
- Bandwidth cost = R (L/C) β
- β: 帯域, L: 入力データbyte, 式は総転送時間((L/C)byteの通信がR回実行)
- この2項目のパレート解を求める
- xがパレート解 $\iff$ Latency costとBandwidth costが共にxを下回る解yが存在しない
定式化
SMT(Satisfiability modulo theories)で定式化
- SAT(充足可能性問題)の拡張
- 全ての制約を満たすように、変数に値を割り振ることができるか、を判定する
- 変数はbool (true/false)や整数、実数を扱える
探索空間の削減のため、次の制約を追加する(k-synchronous)
- (S ≤ )R ≤ S + k (k: ハイパラ)

| 制約 | 説明 |
|---|---|
| C1 | 通信開始時ににデータ$c$を保持している |
| C2 | 通信終了までにデータ$c$を保持する必要がある |
| C3 | 通信開始前にデータ$c$を保持していなければ,他のノードからそのデータを受け取る必要がある |
| C4 | ノード$n$が$n’$にデータ$c$を送る場合は$n$は$n’$よりも前にデータcを保持している必要がある |
| C5 | stage内で送信できるデータ数は、そのstageのround数$r_s$に制限される |
| C6 | round数の総和を$R$に固定 |
パレート解探索
ハイパラ(S, R, C)の範囲を決める
S: stage数, R: round数, C: chunk数
- Sの下限: a_l = 直径(ノードペア間の最大ホップ数)
- Rの範囲: S ≤ R ≤ S + k
- Cの上限限: R/C \geq b_l := bisection bandwidthの逆数

ソースコードはこちら
疑似コードと違いますが,,,
Combining Collective
non-combining集団アルゴリズムを反転させる
- Scatter ← Gather
- Reduce ← Broadcast
- Reduce-Scatter ← Allgather
- Allreduce ← Allgather + Reduce-Scatter
Result
以下、数値実験結果の紹介。ただ、次の点が不明。
- latencyのみを比較? なぜか
- DGX-1とGigabyte Z52のどちらの結果を使用?(もしかして、混ぜて評価してる?)
- cudamemcpyは具体的にどのような動作を加えた結果になっている?
全体的には小さいメッセージサイズでは、Latensy optimalが良く、大きなメッセージサイズではBandwidth Optimalの結果が良い
Allgather
- SCCL is up-to 2.2× faster than NCCL’s Allgather on small sizes and 1.14× faster on larger sizes

Allreduce
- SCCL beats NCCL’s Allreduce with an 8-chunk algorithm for small sizes by up-to 1.8× and with a 48-chunk for large input sizes by up-to 1.06×

Alltoall
- a speedup of over 6.8× for large input sizes and over 1.4× for small input sizes,

Allgather

*1:https://www.nvidia.com/ja-jp/data-center/dgx-1/
*2:snd${n, c, n'}$) $\land$ (time ${c, n'} = s$