url: https://onlinelibrary.wiley.com/doi/am-pdf/10.1002/cpe.5574
- どんなもの?
- 論文メタ情報
- Background and Related Work
- アルゴリズムの解析
- 既存Allreduceスケジュール
- 提案Allreduceスケジュール
- Pipelined Implementation
- Evaluation
どんなもの?
- ノード内(intra node)とノード間(inter node)の帯域差を考慮したAllreduceアルゴリズムの提案とその解析
- ノード間通信が小さくなるように intra node → inter node → intra nodeと通信を行う
- SimGridによりシミュレーション解析
論文メタ情報
Background and Related Work
現在のGPUクラスタ構成は複数ノードで構成される。 上段がnode内のGPU構成、下段がnode間の接続。

NCCLではringベースのAllreduceアルゴリズムを提供、logical ring(赤い点線)と呼ばれるノード間をまたがるGPU-ring列を仮想的に構築しアルゴリズムを実行する。 しかしこのring内にinter-node間のリンクが含まれるためここで律速してしまう。下図は4ノードからなるlogical ringの例。

アルゴリズムの解析
アルゴリズムのコストモデルとしてalpha-betaモデルがよく利用される。 これは遅延コストと帯域コストの2次元で記述される。
遅延コストはデータの転送回数(=同期数)に比例するコストであり、データの転送初期化コストなどに依存する。 帯域コストはデータ(ビット列)を転送している時間によるコストであり、データサイズと帯域に依存する。
この遅延コストと帯域コストはトレードオフの関係にある。これの直感的な理解を次に述べる。 帯域コストを小さくするには、なるべく必要最低限のデータを送受信する必要がある。このためには細切れに何度もデータを送る必要があり、そのため遅延コストが大きくなる。
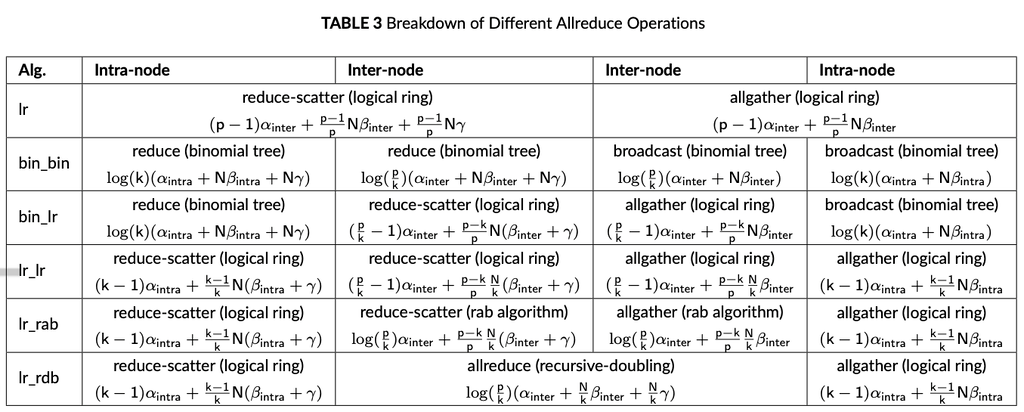
下図はよく知られたAllreduceアルゴリズムの解析。 ただ、これらは同じ帯域であることを前提に記述されている。
- alpha … 転送回数(step数)
- beta … 帯域の逆数
- gamma … 計算コスト
- N … Allreduceサイズ

ネットワークごとのalphaとbetaの値。NVLINKのalphaはほぼ0なのですね。

GPUクラスタの構成では、とくにノード間通信におけるlatency, bandwidthコストに気をつける必要がある。
既存Allreduceスケジュール
S-Caffe 16 and IBM MXNET frameworks でのアプローチ
- ノード内に一つleaderプロセスを決める。
- ノード内でそのleaderにデータを集約
- leaderプロセス同士でAllreduce (これによりglobalデータの簡約値がleaderプロセスに格納)
- ノード内で結果をBroadcast
ノード間Allreduceに参加するプロセス数(p)が減るので、真ん中のphaseにおける全てのノードでAllreduceするよりもlatencyとbandwidthは減少する。ただleader processのAllreduceの最中に、leader以外のプロセスやノード内ネットワークは待ちになるため、この資源を有効活用できてはいない。

Data-Partitioning Multi-Leader
leaderを増やそうという試み。 前提としてノード内のGPUは同じメモリ空間に(Shared memory)にアクセスできるとする。
- まずGPUは共有メモリに自身のデータをコピー(ここでコピーコスト)
- そして自身のchunkに相当するデータを持ってきて、それぞれのプロセスでreduction(図ではデータを4分割)

- その後、ノード間で通信、indexが同じ(同じ箇所)のGPUグループでAllreduceを行う
- その後ノード内でまた共有メモリを介してデータを共有することでAllreduce終了
共有メモリでデータをコピーする際のコストが無視できない(とくに深層学習では多くのデータをAllreduceさせるのでこのコピー時のデータ転送コストが大きい)

提案Allreduceスケジュール
共有メモリを持たない分散メモリ環境でのmulti-leader戦略の提案

こんな感じのノード内→ノード間→ノード内、スケジュールを色々な組み合わせで作る。
bin-bin スケジュール
例えばbin-binスケジュールは次のようになる。

Pipelined Implementation
上記のスケジュールは基本的にintra → inter → intraの順序。全体の時間を黒→赤に短縮できる。

S (chunk数) = 2 におけるbin-binスケジュールのパイプラインの様子。

Evaluation
ここではどのように実験をしたかと主要な結果の一部のみ記載する。
SimGrid framework 2 version 3.19を使ってシミュレーションを行った。 データサイズは数MBから数百MBのAllreduceで実行
- すべてのアーキテクチャについて、Infiniband EDR35、Omni-pathスイッチ、PLXスイッチ36の実際のスイッチ遅延が約90から110 nsであることを考慮して、すべてのスイッチの遅延を約100ナノ秒(ns)に設定。
- ノード間、PCIe、NVLinkリンクのリンク帯域幅をそれぞれ12.5 GB、16 GB、50 GBに設定。
- オンノードアーキテクチャについては、単精度30で9.3 TFlopsに達するNVIDIA Tesla P100を使用。
- これらのネットワークは、すべてのケーブル長が5メートルであるという強い仮定のもとで物理的なレイアウトに配置。
- また、Floydアルゴリズムに基づく最小のルーティングでSimgridを設定。
ここではbin_binをベースラインとしている。(lr, rab(Rabenseifner)が単体アルゴリズムでありベースラインな気がするが)
実行時間について

Network Power Consumption
ネットワークの消費電力のみ計測、計算処理の消費電力は無視(それでいいのかという議論はある)。 Simgridに消費電力の計測の機能があるらしい(式やパラメータはユーザー指定か?)

phi is the normalized link utilization obtained by dividing the link load to its bandwidth. P_dynamicは peak時と待機時の消費電力をリンク使用率で線形補間したもの
- NVIDIA Tesla P100には4つのNVLINKがあり、1つのリンクあたり16レーンがあるため、各レーンが約0.7ワット、各リンクが約0.7×16 = 11.2ワットを消費すると仮定
- NVLINKとPCIeは負荷がないときにピークエネルギーの85%を消費すると仮定
- さらに、PCIe、スパインスイッチ、リーフスイッチのピークパワーとアイドルパワーを、それぞれの最大電力消費量と典型的な電力消費量をポート数で割ることで求める
- multi-leaderではより多くのプロセスがノード間通信に参加するため、全体の電力消費が増える傾向にあるみたい


Pipelinenの効果
