概要
背景
- シングルプロセッサコアのクロック上昇率が頭打ちのため,並列処理による性能向上が必要となっている
- しかしながら、複数コアを繋ぐインターコネクトで(クロスバーやFat Treeで)フルバイセクションバンド幅を実現することがコスト的に困難
- バンド幅に非対称性を持たせたとしても(上流帯域を太くしない)、結局ストレージ通信も同じネットワークを使用する場合、通信性能低下が避けられない
- そこで、次世代インターコネクトとしてEPSとOCSのハイブリッドが提案されている
- (Electronic Packet Switching: EPS) ネットワーク: 安価な低バンド幅電気パケット
- (Optical Circuit Switching: OCS) ネットワーク: 高バンド幅光サーキット
どんなもの?
- EPS ネットワークと小規模OCS ネットワークを組み合わせたハイブリッドインターコネクト上におけるMPI用メッセージ通信方法を提案
技術や手法のキモはどこ?
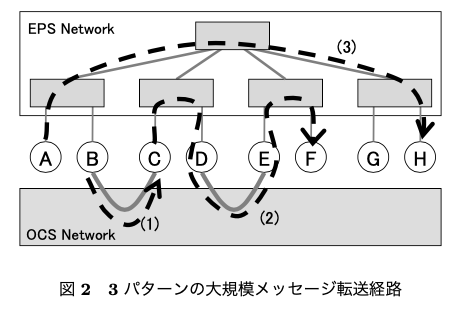
- EPSとOCSを組み合わせて3パターンのルーティング(下記)をベースに
- OCS ネットワーク上での直接通信経路
- OCSとEPSどちらの経路も通る
- EPSオンリー
- OCSを用いてどのノードとどのノードを接続すれば良いか?を決める手法を提案
どうやって有効だと検証した?
- 自作シミュレータで実施
- (確実に明記はされていないが)NAS Parallel Benchmarks(NPB) [6] MG(Multigrid: 3 次元ポアソン方程式のマルチグリッ ド法に基づく解法)実行時のプロファイルを元にシミュレーションしている
OCS経路選択アルゴリズム
Switch Partitioning
EPSに繋がれたrankをグループとする。下の図だとグループ数は4。異なるグループ間の通信が発生した場合、(すなわちEPSを跨ぐ通信が発生した場合)そのグループ間にOCS経路を生成する。具体的にグループ内のどのrankとrankを結ぶかは事前に決めておいたルールに従う(最も小さいrankを選択するなど)

Communication Partitioning
事前に取得した通信パターンを取得。まずお互いの通信が多いrankをEPSグループにまとめる。これはグラフ分割を用いて実行。それ以外の通信経路をOCS上に構築。
フォワーディングテーブルの作成
メッセージ中継のためのフォワーディングテーブルは、バンド幅を基準とした距離ベクトル型アルゴリズムを用いて作成され、EPSネットワーク上流リンクより光回線を優先使用するルールとする。中継ノードは経路情報を交換してフォワーディングテーブルを更新することで、経路情報を同一EPSスイッチ下のノードに送信する。EPSネットワーク上流リンクを用いるのは、回線数が足りず、孤立してしまったスイッチ下ノードへの通信に限られる。
関連研究におけるネットワークトポロジ
EPSとOCSハイブリッドのネットワークトポロジを紹介。
Barker らの複数 OCS ネットワーク
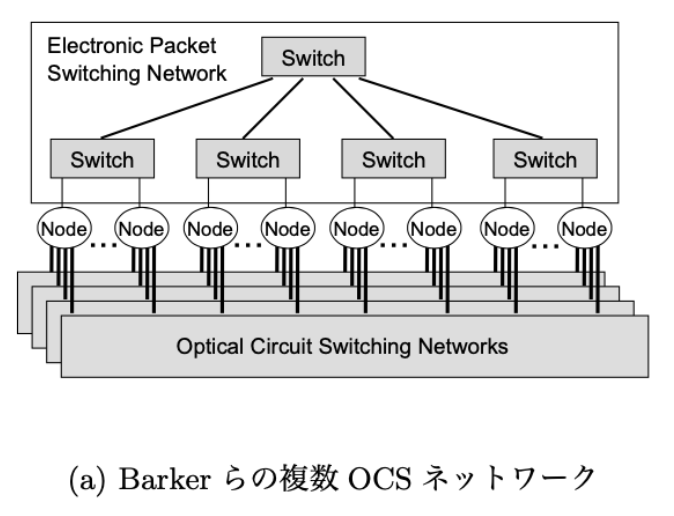
(a) 一対一通信はまず EPS ネットワークを用いて開始。 トラヒックを監視しつつ、データ量が増加した場合に、光回線を確立しOCS ネットワーク上での通信に切り替える。全ての光回線を使いきっている場合には、LRU(Least Recently Used) ルール等に従い古い回線を解放し、 新規に回線を確立する。一方,集団通信はEPS ネッ トワーク上でのみ行われる. MPI 通信に関してはノードが 電気・光間の中継を行わない点,集団通信を EPS ネットワーク上だけで行う点が本研究とは異なる。
HFASTとEPS ネットワーク
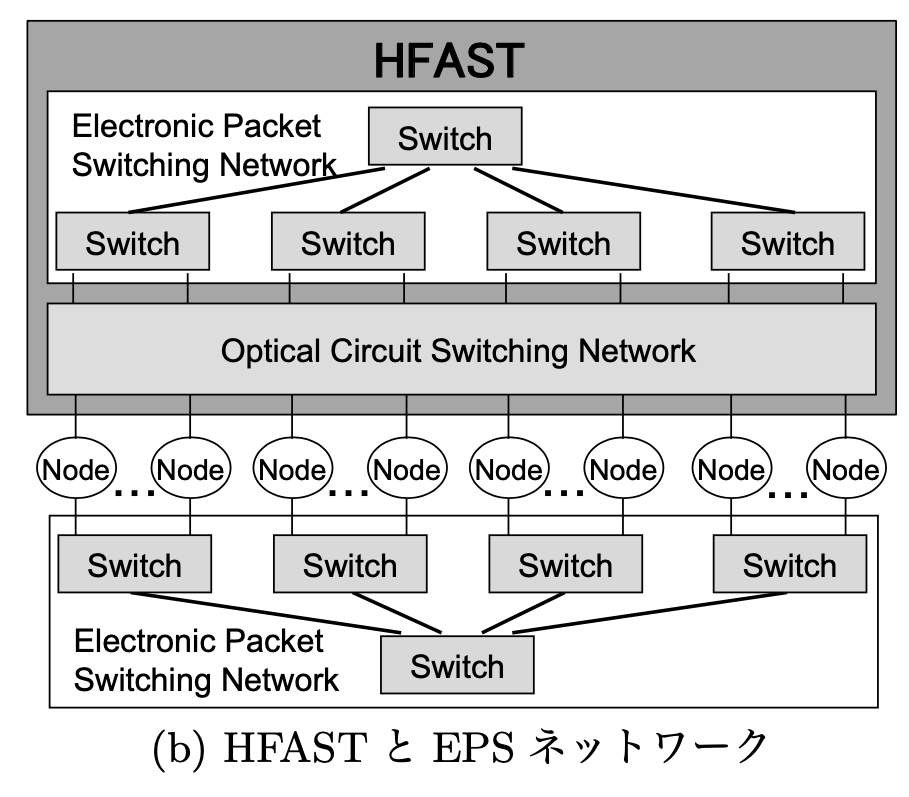
(b) HFASTはEPS ネット ワークと計算ノードの間にコネクションプールとして OCS ネットワークを挿入する構成。従来のネットワークを用いた場合には局所性のあるノー ド同士の通信を最適化するためにはタスクマイグレー ションが用いられていたが、HFASTを用いれば光回線の割り当て問題となり、軽量な通信最適化が可能。
EPSスイッチ間光ネットワーク
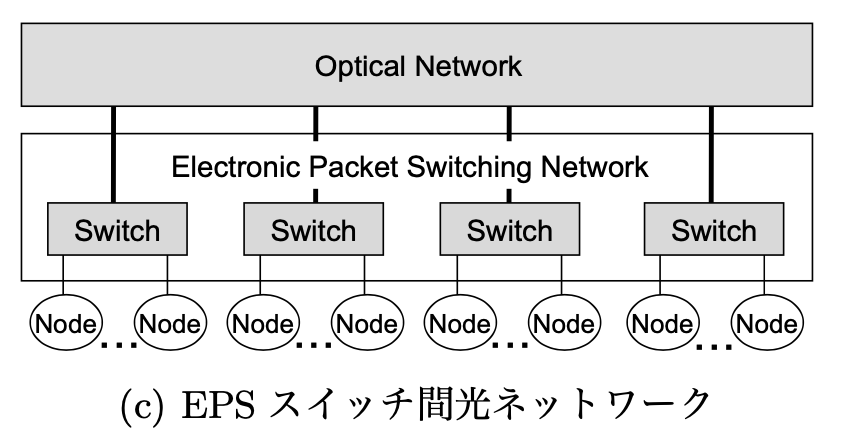
(c) 上流リンクバンド幅を増強した EPS ネットワークと等価。この場合、任意のノード間の通信を実現するには、常にEPS スイッチ間を光ネットワークで全対全で接続する必要があり、EPS スイッチ数が多い場合には複雑なトポロジとなる。また、隣接通信の結果から、このような構成のト ポロジに対する我々の提案手法の優位性は示されている。
光のみのネットワーク
(d)リングトポロジ型光ネットワーク上に構成された共有メモリインターフェースを介して通信。しかし、リングネットワーク上の通信は 単一トークンパッシング方式であり、1 度に 1 ノードしか通信を行えないため、EPS ネットワークを用いた場合より実行性能が落ちている。この性能低下はMPI Alltoall のように、全対全でメッセージを交換し合う場合に特に顕著に現れると考えられる。ノードのリンク数を増やして複数リングを作り、通信性能を 上げることは可能だと考えられるが、そのためには大規模な光ネットワークが必要となる。しかし、それでも多くのノード間の全対全接続は困難である。