@inproceedings{ren2021zero,
title={$\{$ZeRO-Offload$\}$: Democratizing $\{$Billion-Scale$\}$ Model Training},
author={Ren, Jie and Rajbhandari, Samyam and Aminabadi, Reza Yazdani and Ruwase, Olatunji and Yang, Shuangyan and Zhang, Minjia and Li, Dong and He, Yuxiong},
booktitle={2021 USENIX Annual Technical Conference (USENIX ATC 21)},
pages={551--564},
year={2021}
}
Paper: https://www.usenix.org/system/files/atc21-ren-jie.pdf presentation: https://youtu.be/Hdzh4fJv4yY
背景
- モデルの巨大化が進行中
- 大きいモデルの方が小さいモデルよりもリソース効率が良い[12]
[12] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020.
どんなもの?
- パラメタの更新をCPU上で行うことで、GPU上に必要なメモリ量を削減し、より巨大なモデルを学習できるようにするテクニック
先行研究と比べてどこがすごい?
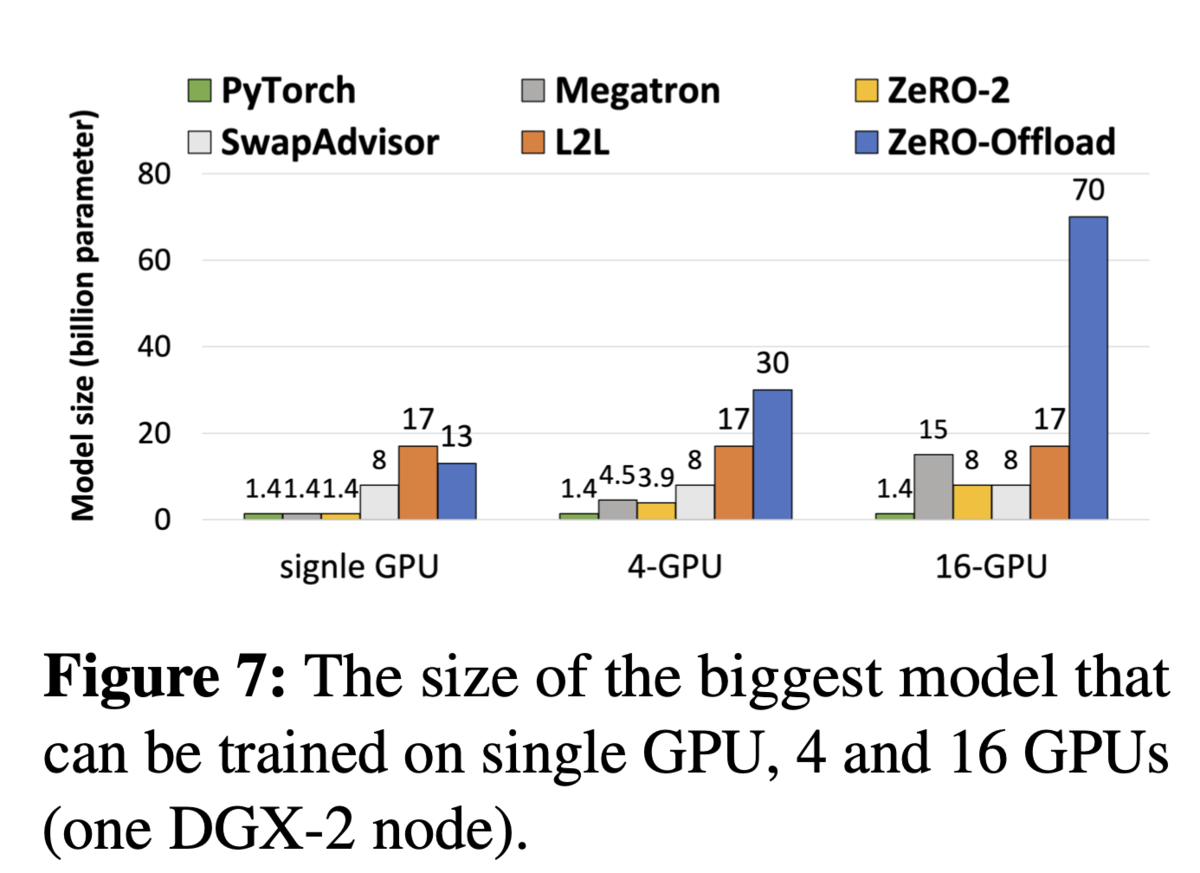
- 理論上における学習可能なモデルサイズを, (PyTorch, Megatron, ZeRO-2, SwapAdvisor, L2L)に比べてかなり上昇させた
技術や手法のキモはどこ?
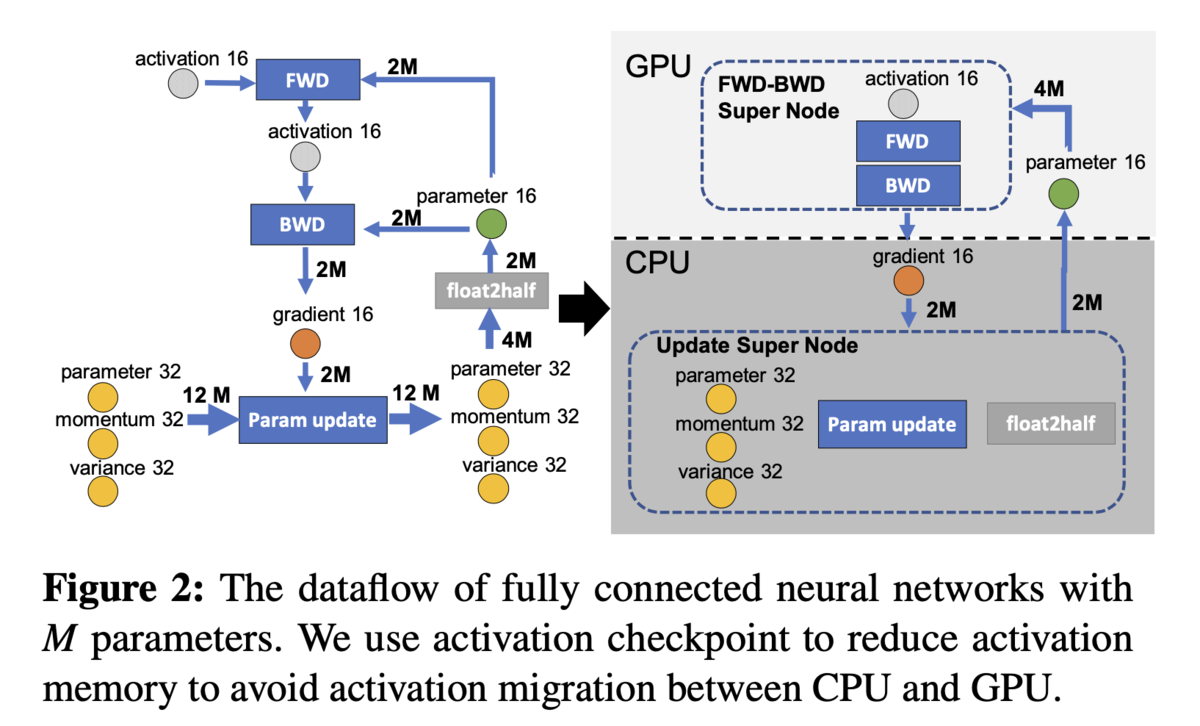
- データや処理の流れをグラフで表現し、GPUとCPUの計算をどこで線引きすれば良いかをグラフ上で議論することで、 処理の線引きに説得力を持たせる
- CPU上でAdamを並列計算(SIMD)で効率的な実装を行なった
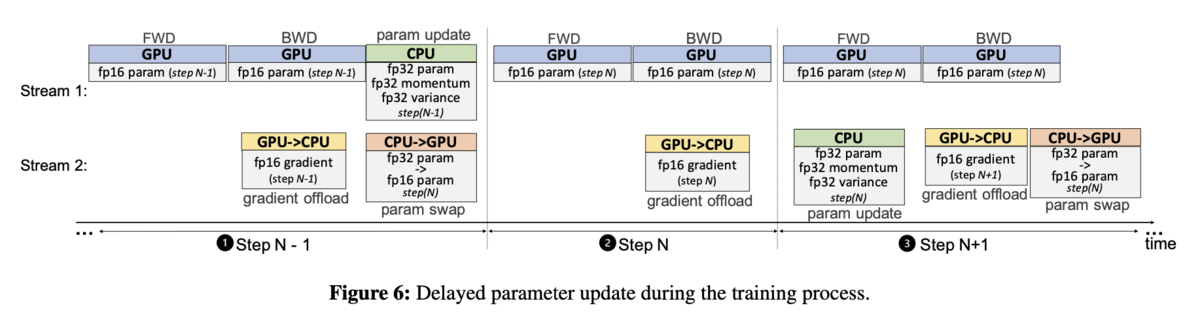
- CPU-GPU通信の遅さを隠蔽するための、one-step delayed parameter update(DPU)
- モデルパラメタの更新とGPU上でのforward/backwardを同時に行えるようになる
どうやって有効だと検証した?
- 比較手法: PyTorch, Megatron, ZeRO-2, SwapAdvisor, L2L
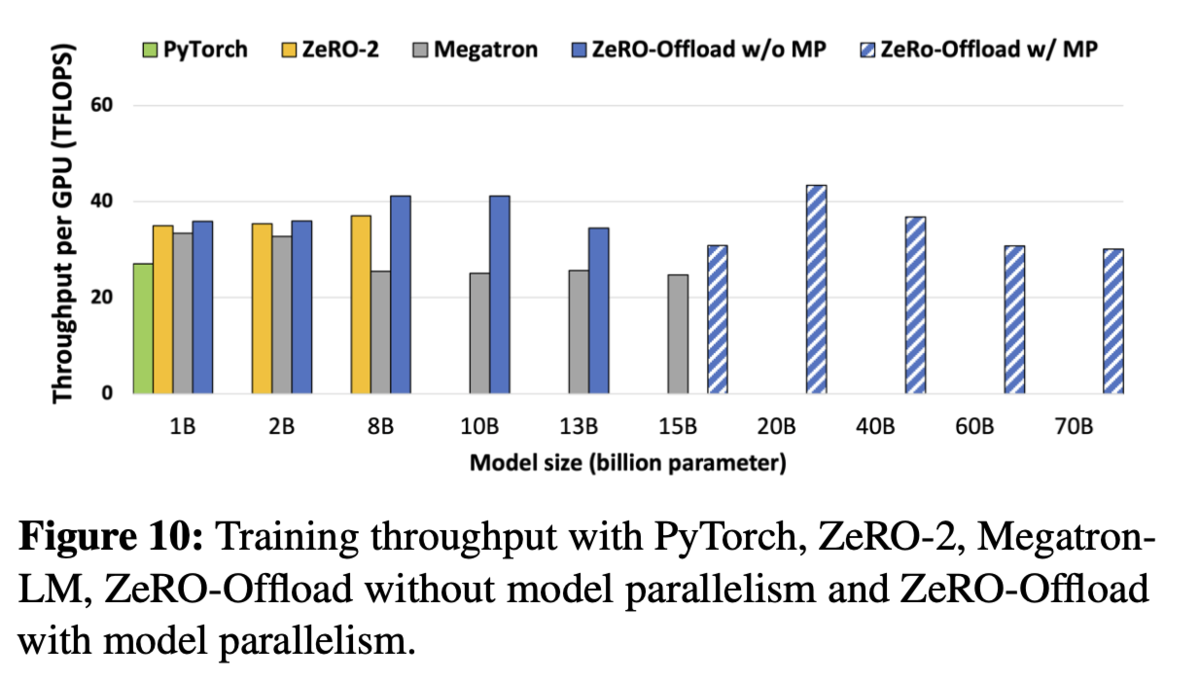
- 最大130億パラメタによるGPTベースのモデルの学習で、スループットが最良であることを示した
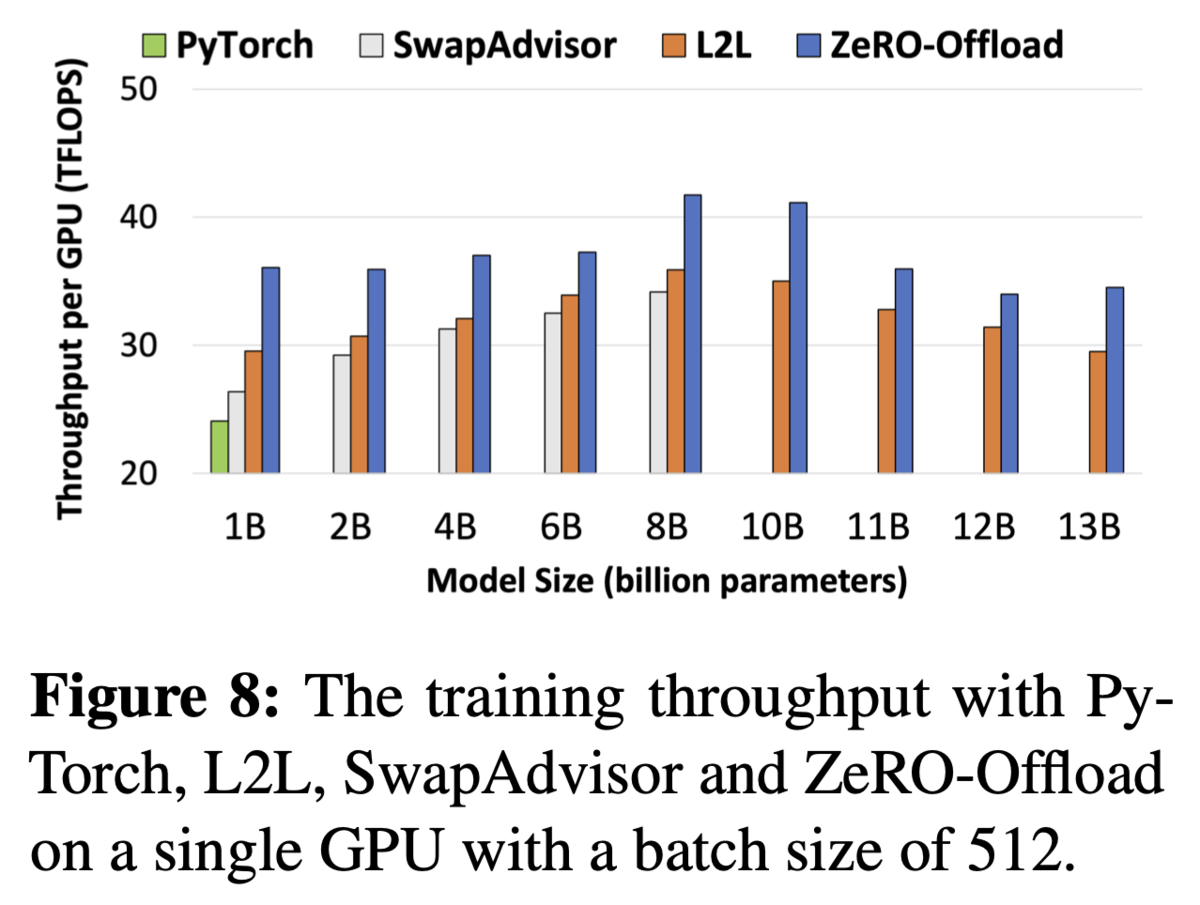
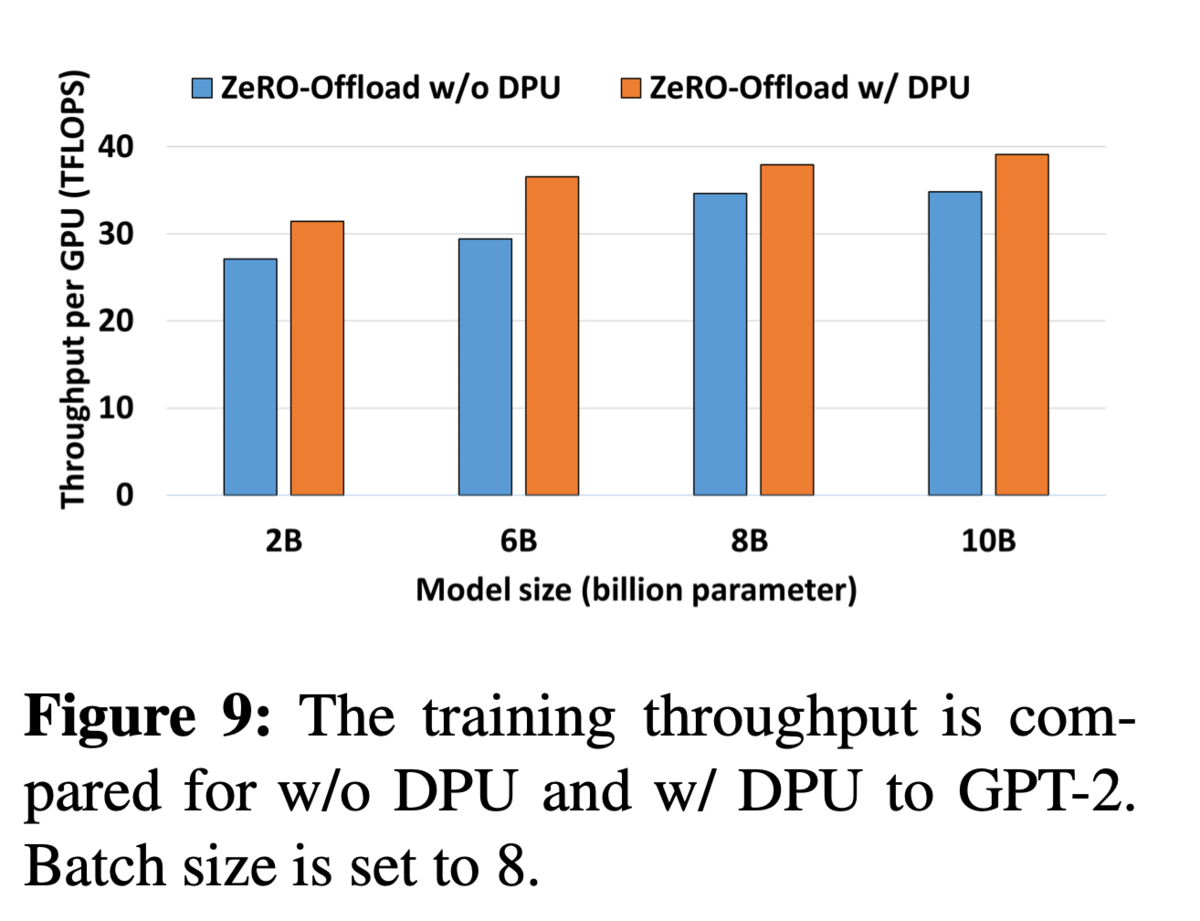
- DPUによりスループットが向上することを確認(GPT-2), またlossやfintuing_loss/step もほぼ変わらないことを確認
- モデルパラレルとの組み合わせで、より大きなモデルを学習できる+スループットはそれほど変わらないことを確認