@article{huang2019gpipe,
title={Gpipe: Efficient training of giant neural networks using pipeline parallelism},
author={Huang, Yanping and Cheng, Youlong and Bapna, Ankur and Firat, Orhan and Chen, Dehao and Chen, Mia and Lee, HyoukJoong and Ngiam, Jiquan and Le, Quoc V and Wu, Yonghui and others},
journal={Advances in neural information processing systems},
volume={32},
year={2019}
}
paper: https://proceedings.neurips.cc/paper/2019/file/093f65e080a295f8076b1c5722a46aa2-Paper.pdf
背景
- モデルの巨大化が進行中(自然言語処理モデルGPT-3は1750億のパラメタを持つ)
- 単一のメモリにモデルが載らないケースも
- モデルを複数の層からなるブロックに分割して、それぞれをデバイスに振り分けることで、メモリ使用量を節約するモデル並列が提案されている
どんなもの?
- 汎用的モデル並列型のパイプライン処理システムGPipeの開発
(図はNarayanan, Deepak, et al. "PipeDream: generalized pipeline parallelism for DNN training." Proceedings of the 27th ACM Symposium on Operating Systems Principles. 2019. から)
先行研究と比べてどこがすごい?
- 一般的な層が連なるモデルであればアーキテクチャやタスクの種類によらず適用可能
- micro-batchの導入により、従来手法より学習の収束が速くなった
技術や手法のキモはどこ?
- mini-batchをさらに細いかいmicro-batchに分割し、
- デバイスにデータをforward/backwardさせる
- 一つのバッチを順に流すのではなく、同時並行に流すことで計算時間を節約する
- 従来はmini-batchの並列順伝播とその集約、パラメタ更新で行っていたが、 経験則的にbatchサイズが大きくなると勾配の平均化が起きて、パラメタ更新が遅くなるらしい
- ここではmini-batchをさらに細かくしたmicro-batchの並列順伝播と集約、パラメタ更新を行うので、勾配の平均化が起きにくい
- liner-scaleのスケーラビリティ達成(デバイスの数に準じたスピードアップ)
- 途中で保持する必要のあるデータ数を減らすことができるため、スケールアップを促進する
- モデルの分割を自動で(ヒューリスティクに)やってくれる(具体的なアルゴリズムの記載なし)

どうやって有効だと検証した?
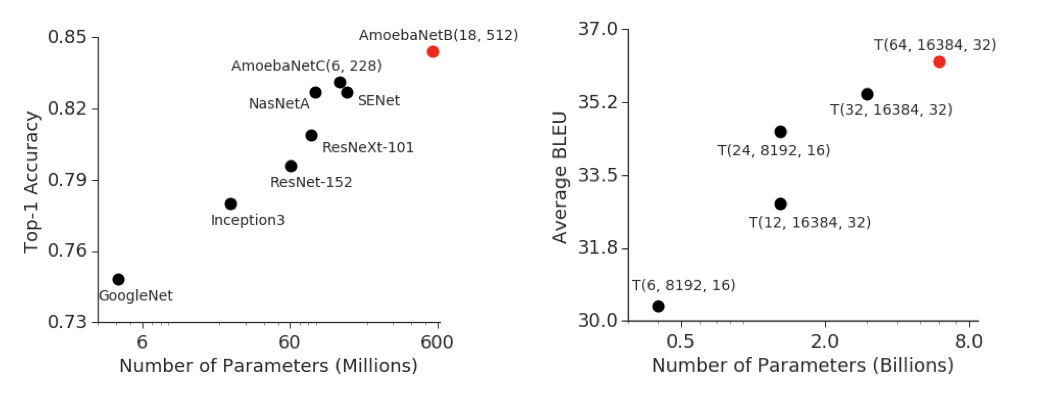
- micro-batchの効果をAmoebaNet(画像分類モデル)、Transformer(NLPモデル)に対して分割数を変えながら実験
- 分割数が大きくなるほどスループットも向上することを確認
- 理論値による学習可能なモデルサイズを報告

- GPipeにより既存ニューラルモデルをスケールアップさせ、そのとき得られた恩恵を確認(いずれも計算時間の記載なし)
議論はある?
- モデルの分割方法については記載なし(heuristic approachとだけ)
- 層(のまとまり)でモデルを分割しているので、一方通行ではない(広域な残渣接続(residual connection))がある場合は単純な適用できない
- 1つのメモリに載りきらないほどのクソでか層があると適用できない
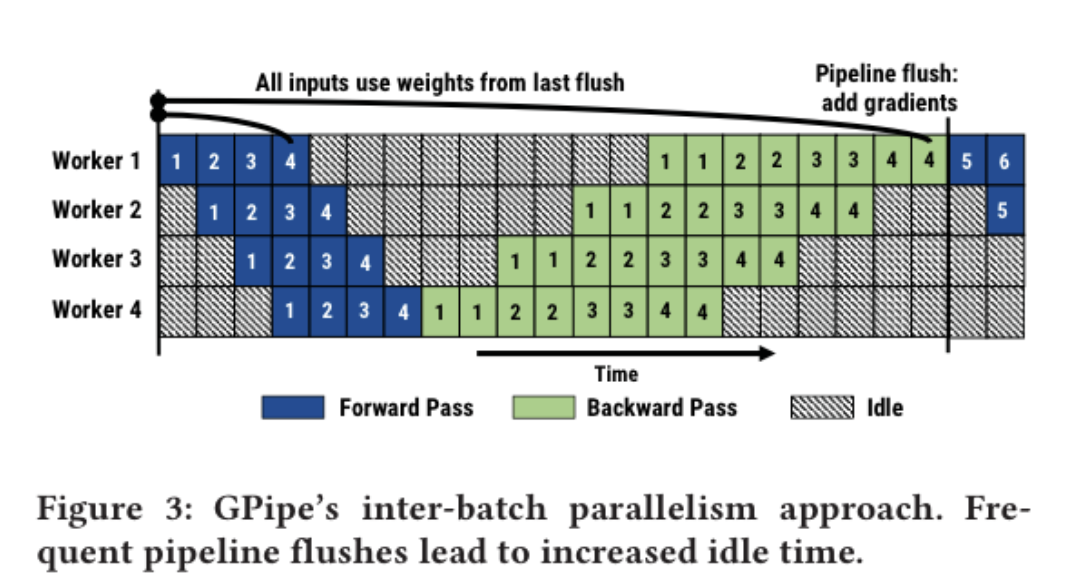
- プロファイルの結果、recompute(backward時に行う計算グラフの再構築, 活性化の状態復元に必要)に全体の計算時間の22.5%も使用されている
- pipeline flush(deviceの同期)の回数が多く、ハードウェア効率が悪くなる

次に読むべき論文は?
- Mesh-Tensorflow、行列演算の並列化、大量のAll-reduce処理が求められるため、適用は高速インターコネクト環境に限定される: Noam Shazeer, Youlong Cheng, Niki Parmar, Dustin Tran, Ashish Vaswani, Penporn Koanan-takool, Peter Hawkins, HyoukJoong Lee, Mingsheng Hong, Cliff Young, et al. Mesh-tensorflow:Deep learning for supercomputers. InNeurips, pages 10414–10423, 2018.
- PipeDream、パラメタサーバの負荷軽減のためのパイプライン処理: Aaron Harlap, Deepak Narayanan, Amar Phanishayee, Vivek Seshadri, Nikhil Devanur, GregGanger, and Phil Gibbons. Pipedream: Fast and efficient pipeline parallel dnn training.arXivpreprint arXiv:1806.03377, 2018.
- re-materialization、メモリロードの節約: Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training deep nets with sublinearmemory cost.arXiv preprint arXiv:1604.06174, 2016.
- そのほかモデル並列に関する論文
- Alex Krizhevsky. One weird trick for parallelizing convolutional neural networks.arXivpreprint arXiv:1404.5997, 2014.
- Seunghak Lee, Jin Kyu Kim, Xun Zheng, Qirong Ho, Garth A Gibson, and Eric P Xing. Onmodel parallelization and scheduling strategies for distributed machine learning. InNeurips,pages 2834–2842, 2014.
- Azalia Mirhoseini, Hieu Pham, Quoc V Le, Benoit Steiner, Rasmus Larsen, Yuefeng Zhou,Naveen Kumar, Mohammad Norouzi, Samy Bengio, and Jeff Dean. Device placement opti-mization with reinforcement learning.arXiv preprint arXiv:1706.04972, 2017.
- Jeffrey Dean, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Marc aurelioRanzato, Andrew Senior, Paul Tucker, Ke Yang, Quoc V. Le, and Andrew Y. Ng. Large scaledistributed deep networks. In F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger,editors,Neurips 25, pages 1223–1231. Curran Associates, Inc., 2012.